技术/笔记/Talent Plan 项目笔记
Project
TinyKV
阅读更多




从文本翻译到文字、语音识别,再到命名实体识别,词性标注,序列标注问题已然渗透到社会生活中的方方面面。不少自然语言处理的问题都可以想方设法转化为序列标注问题:对邮件等”大块“的信息做命名实体识别,识别出信息中的表单项用于自动填写表单,可以有效地提高工作效率,节约时间;对音频文件进行标注分析,可以用来进行语音识别;抽取出来的电子病历文本中的疾病、治疗、检查等类型的实体,可以用以对电子病历进行分类归档…想要处理好一般性的自然语言处理问题到序列标记问题的转化,关键在于处理好如何定义标记的问题。
朴素贝叶斯公式求后验概率
其中 为文档, 为分类。文档是词的合集,提取特征 ,即文档由n个词 token(可重复)组成。做独立性假设后公式可化简为:
由于需要知道的是文档最有可能的分类,因此实际上是求 ,又因为 不变,因此也就是求:
用词 在类别 的文档中的占比来估计, 用类别 的文档在所有文档中比重来估计。并且为了避免个别 导致错误,对单词频数加1进行平滑:
\hat{P}(t_j|c_i) & = \frac{N(t=t_j,\space c=c_i)+1}{\sum_{t_k \in V_i} (N(t=t_k,\space c=c_i)+1)} \\ & = \frac{N(t=t_j,\space c=c_i)+1}{N(c=c_i)+|V_i|}
其中 为 类文章中 出现的次数, 为出现在所有类型为 的文档中的单词集合(不重复), 为不重复单词数。
Job1:统计
Mapper<Text, Writable, Text, Writable>
InputFormat,只读取文件所在目录名而不读取内容,并且规定split不会切分文件,防止统计冗余1Reducer<Text, List<Writable>
<类别, 总数>Job2:统计
Mapper<LongWritable, Text, Text, IntWritable>
TextInputFormatRecordReader 按行读取(使用TextInputFormat),一行一个单词,同时读取split包含的文件名作为类别,将类别和单词用-拼接成一个Text类型变量作为Key输出1 即可Reducer< Text, List<IntWritable> >
< 类别-单词, 总数 >Job3: 统计
输入job2的output
Mapper<Text, IntWritable>
<类别,个数>Reducer 输入<类别, list{个数}>,输出<类别, 个数求和>
Job3:测试
winutils.exe,hadoop.dll等文件
%HADOOP_HOME%
Cygwin 环境执行 Hadoop 命令会产生路径问题,导致无法正确加载类1 | |
运行相应的启动脚本以启动 Hadoop 相应服务:$ hadoop-3.3.5\sbin\start-xxx.cmd
sbin\start-dfs.cmdWin 下使用 hdfs dfs 命令行的 -put 和 -get 命令时,指定本地路径时不能使用相对路径
开启dfs后无法写入:离开NameNode安全模式 hdfs dfsadmin -safemode leave
NBCorpus\Country\AUSTR、NBCorpus\Country\BRAZ和BCorpus\Country\CANA三个目录中的文件作为训练数据,分类的class为AUSTER和CANA| 类别 | 训练集数目 | 测试集数目 |
|---|---|---|
| AUSTR | 244 | 61 |
| BRAZ | 160 | 40 |
| CANA | 211 | 52 |
NaiveBayes.java,实现朴素贝叶斯分类器算法。另一个是本地控制台程序 Predictor.java ,根据测试集预测并输出评估指标。NaiveBayes.java 实现三个 job,输入分好词的文件(训练集),以文本形式将统计结果输出到三个文件夹中。Predictor.java 根据测试集文件夹内容对每个文件进行预测,产生混淆矩阵,并计算每个类别对应的 Precision、Recall和F1值,最后还会输出指标平均值。NaiveBayes.java 文件(或者在IDEA中编译),获得一系列字节码文件 NaiveBayes*.class1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
Predictor.java 查看预测结果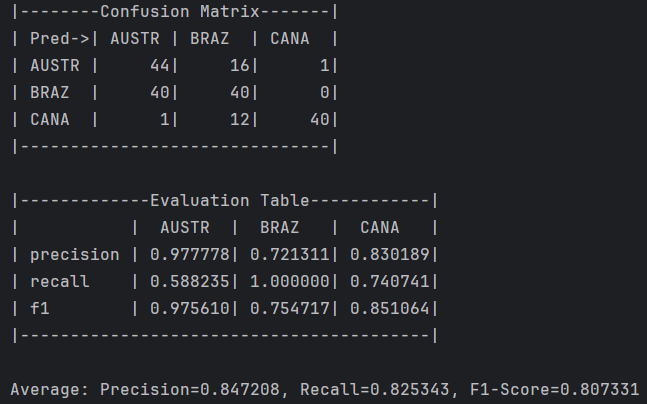
Update your browser to view this website correctly.&npsb;Update my browser now