
技术/笔记/Talent Plan 项目笔记
Project 1
-
[x] 熟悉整个 tinykv 的框架
- 一个 TinyKv Node 从高到低分三层:Server、Storage、Engine,此外还加上一个 TinyScheduler 组件负责管理 TinyKv 集群
- TinySQL 在此次项目中无需实现,值得注意的是 TinySQL 是通过 远端调用 RPC 的方式使用 TinyKv 的
- Server 层的接受远程请求,依此调用 Storage 层来提供存取服务
- Raw API 提供基本的 GET、PUT、DELETE、SCAN 服务
- Txn API 提供事务支持
- Coproceccor
- Transaction
- MVCC 提供多版本管理服务
- Storage 层在 Engine 层的基础上实现 raft 分布式存储 (单机存储引擎 StandAloneStorage 不需要实现 raft,只是单纯的封装Engine 层)
- Engine 层为最底层,提供基本的键值存储引擎服务(项目中直接使用 badger 作为存储引擎)
-
[x] 了解
raft算法基本原理 -
[x] 熟悉
badger api和 tinykv 项目模板提供的engine_util包 -
[x] 实现 Storage 层的单机存储引擎
StandAloneStorage -
badger 的只读事务会使用到存储快照,保证了批量读取的一致性(读到的是同一时间点的快照),因此读取操作均借助 badger 事务
badger.Txn来实现 -
列族 Column Family,相当于 key 的名称空间,Storage 需要在 Engine 层的基础上封装对列族的支持(存取操作都要指定 列族 CF)
-
[x] 实现 Server 层的
Raw API -
[ ] 存储引擎相关:LSM-Tree
-
[ ] 序列化与远程过程调用相关:ProtoBuffer & gRPC
参考文献
- Raft 基本介绍与可视化:Raft Consensus Algorithm
- TinyKv 和 TiKv很像,因此可以参考:三篇文章了解 TiDB 技术内幕 - 说存储 | PingCAP
- badger package
- 网课: https://learn.pingcap.com/learner/course/510001
Project 2
2A Raft 算法
主要是处理各种情况下的 Message
如何处理 Message ?按优先级参考以下来源:
- 测试函数 (最具体)
- doc.go (大体思路)
- raft 论文 (学习思想、关乎安全性的设计)
对于某些特殊情况可以考虑用 raft 官网上的交互式系统(Raft Visualization)模拟出相应情形加深理解
- 调用关系图
- RaftLog:实现了一个日志,包含对日志的一系列增删查改的操作
- Raft:实现 raft 算法,
tick()时钟步进,step()处理信号(本地消息直接step,msg中的消息是要发送的消息) - RawNode:在
Raft基础上进一步封装,方便上层应用调用(ready,advance)
- 关于空日志 noop entry 的定义
1 | |
- 注意集群中只有单个节点的情况(此时无需广播append消息、选举直接晋升leader无需广播reqVote等等)
- 过半否决:Candidate 发起一次投票后如果收到了半数 Reject 则直接变为 Follower,因此要在 Raft 结构体中新增相应的字段记录一轮投票中的否决票数
- 关于过半 Commit :可以在每次收到 AppendResponse 之后按照 Prs 大小从低到高排序,然后取中间值 Commit(过半以上的节点至少复制到了该索引值以前的日志)
- heartbeat和append的区别
- heartbeat
- 间隔一定周期主动发送
- 维持节点间的主从关系
- 被动同步:从节点接受到主节点的心跳后发现日志并不同步于是通过HeartbeatResponse反映给主节点让其发起appendEntries同步日志
- appendEntries
- 主动同步:主节点在 propose entries (新增日志)后主动发送直到从节点同步为止
- heartbeat
- 2ac中,ready中的条目是相较于上次调用ready的“更新”的内容,因此需要保存过去的HardState和SoftState的副本,以便比较当前HS和SS是否是有所变化,如果没有变化则置为默认初始值(而不是一股脑地赋值为当前raft的state)
2B Raft Storage
主要内容:驱动Raft模块服务各种Requast并返回Response。
大致思路:接受客户请求,分发请求到对应Region的Leader,包装请求成为
raftlog并驱动Leader发起Propose,等待日志一致(commited)后对节点的一些数据持久化(raftlog,applyindex,hardstate等),然后将已经提交的raftlog应用到状态机,最后返回响应,驱动raft模块进行下一步处理(RawNode.advance())
代码框架
raft_server.go:前端,对外提供访存接口,对内发送请求transport.go对外发送消息的接口,面向整个raft集群raftstore.go:后端,管理peer节点,启动worker,接收来自前端的请求,分发到对应peer-
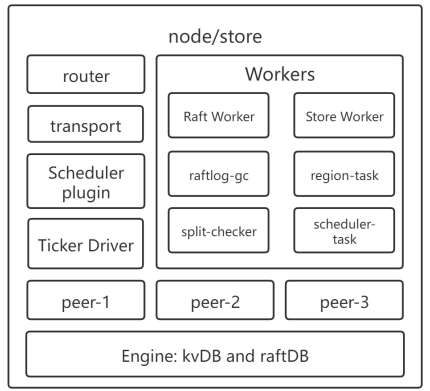
peer.gopeer_storage.go管理peer的存储引擎(分为kvDB和raftDB,kvDB相当于raft论文描述的状态机,raftDB存储raft模块里需要持久化的数据方便重启恢复数据)peer_msg_handler.go处理来自上层的请求
xxxworker.go各种worker的实现raft_worker.goraftstore 中实现了接收、分发、处理消息的线程
router.gonode/store 内部消息路由,面向单个raft节点ticker.go计时模块
-
注意事项
-
应用committedEntry的时候需要将appliedState以及Put、Delete等写入操作对KVDB的修改写到同一个WriteBatch中,然后一起writeToDB,以保证原子性(防止apply异常而appliedIndex更新导致的不一致性)
-
Snap Request 要求返回一个Transaction用于读取数据,同样也是为了保证读取的数据时间上的一致性
-
raft_server.go中似乎没有包装过Get类型的Request,但是测试函数里会发送Get Request。GetResponse中的Value也应当来自于同一个Transaction保证一致性
-
持久化时写入database的key值要遵循下表的格式
- 可以采用meta包中的工具函数将
region_id&log_idx转化为对应的key
Key KeyFormat Value DB raft_log_key 0x01 0x02 region_id 0x01 log_idx Entry raft raft_state_key 0x01 0x02 region_id 0x02 RaftLocalState raft apply_state_key 0x01 0x02 region_id 0x03 RaftApplyState kv region_state_key 0x01 0x03 region_id 0x01 RegionLocalState kv - 可以采用meta包中的工具函数将
2C Snapshot & LogCompact
-
日志压缩 LogCompact
RaftGCLogTick定时检查日志长度,超过一定长度后会发出一个CompactLog的AdminRequest(注意这种request也是要作为日志复制到集群中其他节点并进行commit后才能应用到状态机),store 处理该request的过程实际上就是截断日志链进行压缩,此过程包括修改applyState和raftState等元数据以及通过ScheduleCompactLog托付给raftlog-gc worker将被截断的entries进行删除。以上过程均发生在store层次。- 除了store要进行日志压缩外,raft模块中的entry也不能无限增长,需要实现raft.raftlog中的
maybeCompact函数对raft模块的日志链进行截断。maybeCompact在Advance时调用。
-
快照发送 Snapshot
- 发送:当Leader需要发送已经被截断的日志时(SendAppendEntry),由于此部分日志已经不存在了,所以 leader 需要通过
storage.Snapshot获取状态机的快照(快照的具体构建和发送逻辑不需要我们来实现)并发送给目标节点 - 接受:store层面,节点要判断ready中是否有待处理的快照(即snapshot字段是否为空),如果有则应用该快照(交付给regionWorker处理)并修改元数据
- 发送:当Leader需要发送已经被截断的日志时(SendAppendEntry),由于此部分日志已经不存在了,所以 leader 需要通过
